




NaiveProxy,挪威语叫NaïveProxy,翻译成中文:“天真的代理”,是2019年底由klzgrad大神开发的一种突破GFW网络审查的新型科学上网代理技术,它使用Chrome的网络堆栈来伪装流量,具有较强的抗审查能力和较低的可检测性,重用Chrome网络堆栈是确保性能和安全性的最佳实践。
NaiveProxy的原理和trojan很像,除去教程搭建的节点消除了服务器tls指纹和隐藏了所有翻墙服务以及伪装成正常网站,NaiveProxy协议更上一层,消除了客户端的tls指纹和tls-in-tls特征,并且naive协议基于http2,自带多路复用,对比ws需要频繁握手来讲延迟更低,前面也说过NaiveProxy客户端使用chrome浏览器内核作为网络协议栈,从防火墙的角度来看,就像是你在正常的使用正常的谷歌浏览器访问正常的网站。
NaiveProxy还可以缓解以下流量攻击:
- 网站指纹识别/流量分类:通过 HTTP/2 中的流量多路复用来缓解。
- TLS参数指纹识别:因重用Chrome的网络堆栈而失败。
- 主动探测:被应用程序前端击败,即通过应用层路由将代理服务器隐藏在常用前端的后面。
- 基于长度的流量分析:通过长度填充缓解。
该代码由一系列补丁程序组成,这些补丁程序在每个新的Chrome版本中都经过了变形和重新设计。
🔗 NaiveProxy项目地址:https://github.com/klzgrad/naiveproxy
1、NaiveProxy的工作原理
工作原理架构:[浏览器 → NaiveProxy客户端] ⟶ GFW ⟶ [常用前端 → NaiveProxy服务端] ⟶ 互联网
由于 NaiveProxy 使用Chrome的网络堆栈,GFW审查截获的流量行为与Chrome和标准前端(如 Caddy、HAProxy)之间的常规 HTTP/2 流量完全相同。前端还会将未经身份验证的用户和活动探测器重新路由到后端HTTP服务器,从而使得无法检测到代理的存在,比如像这样:探查⟶常用前端⟶网站页面。
从 NaiveProxy V84 版本开始,用户可以在没有Naive服务器的情况下运行Caddy转发代理的Naive分支。
2、NaiveProxy与Trojan的优点与区别
Trojan最大的优点就是伪装成互联网最常见的HTTPS流量,而NaiveProxy最大的优势不仅伪装成 HTTP/2 的流量,而且使用互联网最常用的浏览器Chrome网络堆栈的指纹,更加难以被识别,而且这些也是Go语言模仿不了的。
3、NaiveProxy服务器搭建教程
编译安装caddy+naive:
# 安装golang
apt install golang-go
go install github.com/caddyserver/xcaddy/cmd/xcaddy@latest
~/go/bin/xcaddy build --with
github.com/caddyserver/forwardproxy@caddy2=github.com/klzgrad/forwardproxy@naive
如果第二条指令执行出错,可以尝试执行go env -w GO111MODULE=on 再重试,还不行的话请自行搜索升级go版本方法
Caddyfile配置:
:443, naive.buliang0.tk #你的域名
tls example@example.com #你的邮箱
route {
forward_proxy {
basic_auth user pass #用户名和密码
hide_ip
hide_via
probe_resistance
}
#支持多用户
forward_proxy {
basic_auth user2 pass2 #用户名和密码
hide_ip
hide_via
probe_resistance
}
reverse_proxy https://demo.cloudreve.org { #伪装网址
header_up Host {upstream_hostport}
header_up X-Forwarded-Host {host}
}
}
caddy常用指令:
# 前台运行caddy
./caddy run
# 后台运行caddy
./caddy start
# 停止caddy
./caddy stop
# 重载配置
./caddy reload
caddy配置守护进程(开机自启):https://github.com/klzgrad/naiveproxy/wiki/Run-Caddy-as-a-daemon
自定义端口:
naive如果要用自定义端口,需要使用json的配置方式,新手可以直接跳过
config.json内容:
//需删除注释内容caddy才能加载
{
"apps": {
"http": {
"servers": {
"srv0": {
"listen": [
":4431" //监听端口
],
"routes": [
{
"handle": [
{
"auth_user_deprecated": "user", //用户名
"auth_pass_deprecated": "pass", //密码
"handler": "forward_proxy",
"hide_ip": true,
"hide_via": true,
"probe_resistance": {}
}
]
},
{
"handle": [
{
"handler": "reverse_proxy",
"headers": {
"request": {
"set": {
"Host": [
"{http.reverse_proxy.upstream.hostport}"
],
"X-Forwarded-Host": [
"{http.request.host}"
]
}
}
},
"transport": {
"protocol": "http",
"tls": {}
},
"upstreams": [
{
"dial": "demo.cloudreve.org:443" //伪装网址
}
]
}
]
}
],
"tls_connection_policies": [
{
"match": {
"sni": [
"naive.buliang0.tk" //域名
]
},
"certificate_selection": {
"any_tag": [
"cert0"
]
}
}
],
"automatic_https": {
"disable": true
}
}
}
},
"tls": {
"certificates": {
"load_files": [
{
"certificate": "a.crt", //公钥
"key": "a.key", //私钥
"tags": [
"cert0"
]
}
]
}
}
}
}
启动服务
nohup ./caddy run --config caddy.json >caddy.log 2<&1 &
安装并启用 BBR 加速
cd /usr/src && wget -N --no-check-certificate "https://raw.githubusercontent.com/chiakge/Linux-NetSpeed/master/tcp.sh" && chmod +x tcp.sh && ./tcp.sh
温馨提醒:如果修改版BBR加速模块工作不正常,请使用原版BBR模块加速。
由于新版本Linux系统自带BBR加速模块,所以你可以直接执行以下命令,启用原版BBR加速。命令如下:
bash -c 'echo "net.core.default_qdisc=fq" >> /etc/sysctl.conf'
bash -c 'echo "net.ipv4.tcp_congestion_control=bbr" >> /etc/sysctl.conf'
sysctl -p
至此,NaiveProxy服务器端就搭建完成了。
客户端配置
1)、Naive客户端:https://github.com/klzgrad/naiveproxy/releases/latest
客户端配置:
{
"listen": "socks://127.0.0.1:1080",
"proxy": "https://user:pass@example.com"
}
2)、Qv2ray 中 NaiveProxy插件:https://www.scwcd.cn/archives/27.html
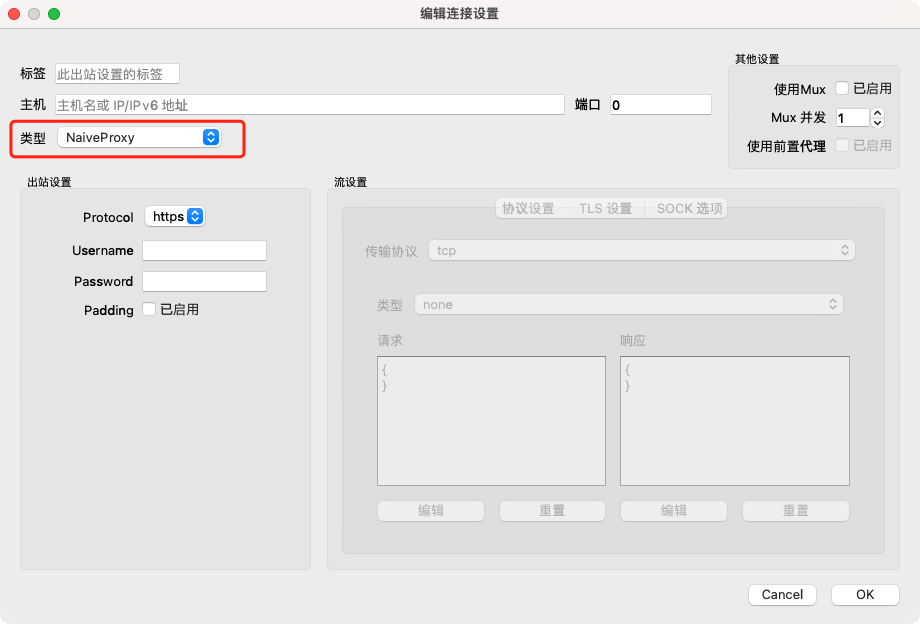
4、TLS指纹查看
jarm工具:https://github.com/salesforce/jarm
网络空间资产搜索引擎:https://fofa.info
# 下载jarm
wget https://raw.githubusercontent.com/salesforce/jarm/master/jarm.py
# 查看网站jarm指纹
python3 jarm.py naive.buliang0.tk
评论区